

由於工作上長期都接觸緊 GenAI,第一下睇完條片嘅反應係:「個 Prompt 都未 Optimize 😂」
非學術 GenAI 一次性「公平」測試
見過好多非學術 GenAI 一次性「公平」測試,操作通常係用一個首選模型,前前後後改咗 N 次 prompt ,調整到出靚效果之後,再將個 prompt 放去其它模型「公平」測試,然後得出最後結論決定用哪一個模型,如下圖:
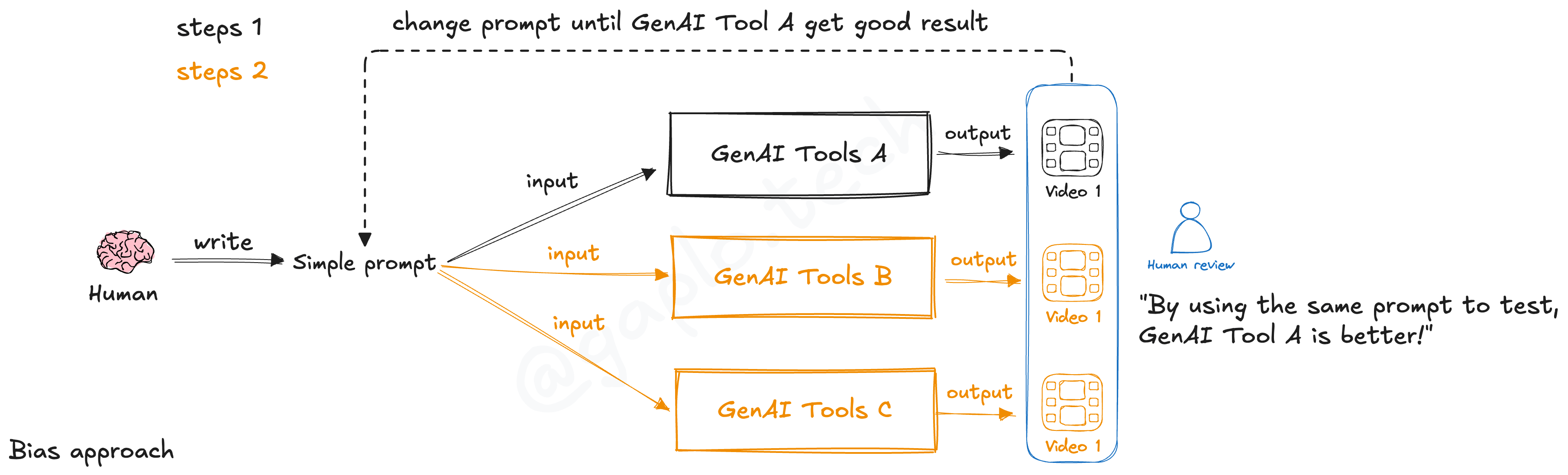
但現時 GenAI video generation 非常依賴 best effort prompt engineering,測試時冇 best effort 就只是 by chance,所以用 1 個 prompt 測試 N 個模型並不是理想測試方法,有極大機會改少少 prompt 之後,生成效果有顯著改善。
言而大部份模型設計或訓練時已經預設有說明書,介紹如何 prompt engineering best practice、解釋不同設定如何影響 generation,但始終人類時間有限,今天 generate 一條 6 秒 video 最少要幾分鐘,如果以下 8 個 GenAI tool 都試 30 次(改 prompt 改 config)嘅話,連同學習及應用 best practices,時間成本太高,不符合出 social post 成本效益。
相對公平方法?
每個 tools 都由「對應專家」花使用相同時間做 N 個 prompt
「對應專家」- LLM
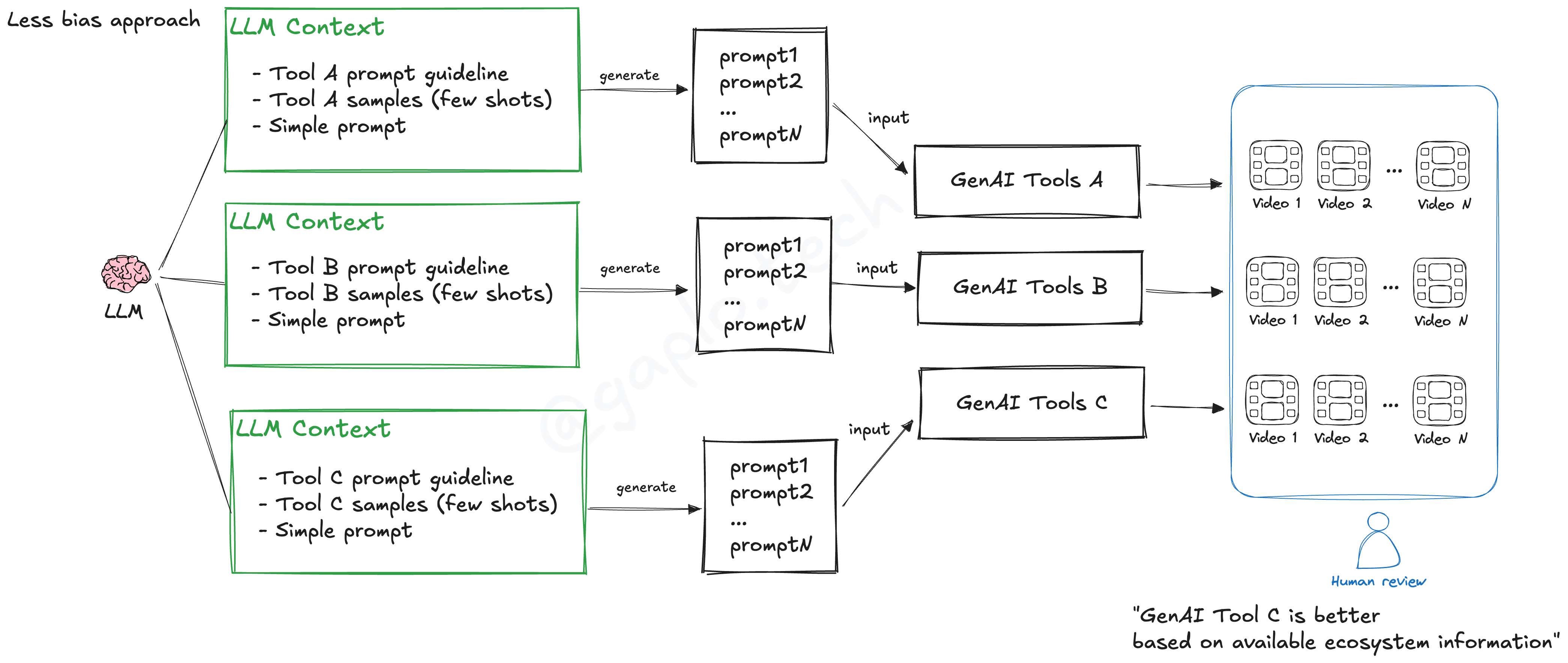
「對應專家」現時最理想是一個 GenAI 再給它 prompting guideline + samples 學習,同時 parallel generate N 個 prompt 再 generate N videos,如下圖:
GenAI 沮喪的地方 - 找 Open Question 的答案
GenAI 時代最尷尬又令人沮喪嘅地方:「模型未必真係做唔到,只係個 Prompt/設定未調較得到。」換句話說,如要用 GenAI 解決一個複雜問題:
由揀模型到 prompt engineering,喺未做到之前都係一條冇正確答案嘅 Open Question。
用一啲 text-to-any 嘅 GenAI 工具,盡可能都會用 LLM generate 一啲 idea 或方向去解決一啲問題,再整合一啲 GenAI 工具說明書列出黎嘅 best practice 及 samples 去 generate 新 prompt。


